Финские учёные, кажется, нашли способ обойти «бутылочное горлышко» производительности, в которое упёрлись современные нейросети. В Университете Аалто придумали, как проводить сложнейшие тензорные вычисления — основу основ ИИ — буквально с помощью света.
Они пропускают световой импульс через систему всего один раз, и операция готова. Звучит почти как фантастика, но эта технология может, наконец, заменить графические процессоры, которые уже дымятся от аппетитов ИИ.
Весь современный ИИ, по сути, держится на тензорных операциях (это такая продвинутая математика с многомерными массивами).
GPU с ними до поры справлялись, но объёмы данных растут лавинообразно, и чипы уже просто не вывозят. Мощности не хватает, а энергопотребление зашкаливает.
Вот эта ситуация и заставила международную команду под руководством доктора Юфэна Чжана искать выход за пределами привычной электроники. Их идея — «однопроходные тензорные вычисления».
Название сложное, но суть изящная. Они берут обычный свет, у которого есть физические свойства — амплитуда и фаза, — и кодируют в них цифровую информацию. А дальше свет просто… летит.
Пока эти модулированные волны распространяются и взаимодействуют друг с другом, они сами, естественным образом, выполняют те же математические расчёты, которые требуются системам глубокого обучения.
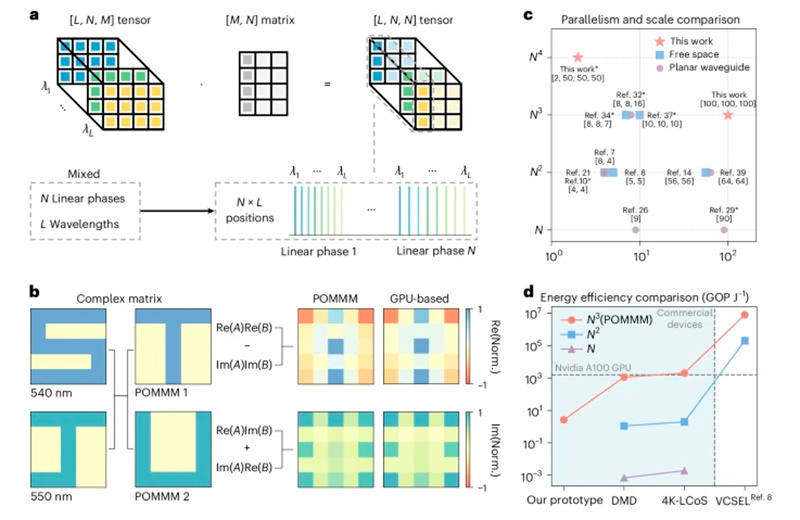
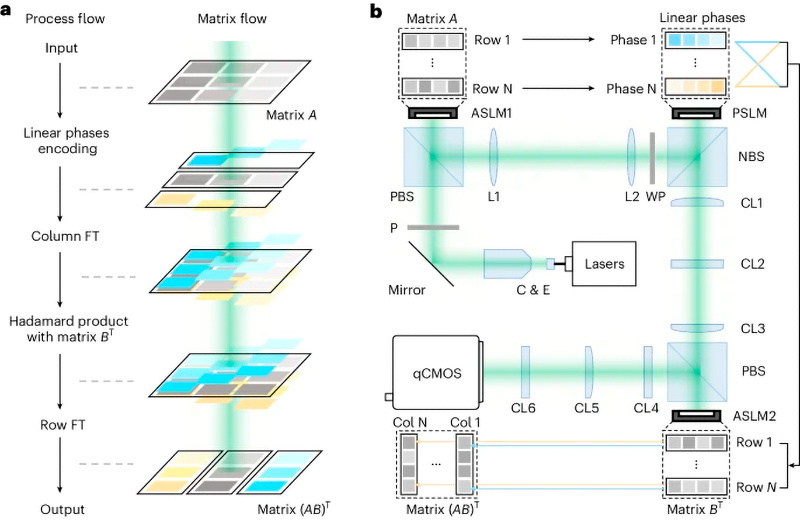
a . Принцип работы POMMM. Слева: последовательность операций POMMM. Справа: соответствующий матричный процесс после каждого шага. Разные цвета соответствуют различным линейным фазовым кодировкам. FT — преобразование Фурье. b . Экспериментальная установка и соответствующие матричные операции. C и E — коллимация и расширение; P — поляризатор; PBS — поляризационный светоделитель; L — линза; WP — волновая пластина; NBS — неполяризованный светоделитель; qCMOS — количественная комплементарная металл-оксид-полупроводниковая камера.
Как объясняет сам доктор Чжан, их метод делает ровно то же, что и GPU — все эти свёртки и слои внимания — только делает это буквально со скоростью света.
И что крайне важно, системе не нужна электронная коммутация (переключения), потому что вычисления происходят физически, пока свет в пути.
Вся «магия» — в простоте
Но исследователи пошли ещё дальше: они «раскрасили» свет, использовав сразу несколько длин волн.
a , Экспериментальные результаты POMMM в сравнении с результатами на основе GPU. Вверху: неотрицательное матричное умножение [20, 20] × [20, 20] (исходное оптическое поле получено на b ). Внизу: действительное матричное умножение [10, 10] × [10, 10] (исходное оптическое поле получено на дополнительном рис. 6 ). Красные элементы представляют отрицательное значение. b , Сравнение между необработанным оптическим полем, полученным камерой qCMOS (внизу), и моделированием (вверху) POMMM. Масштабная линейка составляет 20 пикселей (92 мкм). Каждая яркая точка соответствует элементу в результирующей матрице. c , Сравнение экспериментальных результатов POMMM и MMM на основе GPU. Слева: средняя средняя абсолютная ошибка (MAE). Справа: средняя нормализованная среднеквадратическая ошибка (RMSE). Горизонтальная ось указывает различные размеры матриц. Каждый столбец показывает среднее значение MAE или RMSE по 50 случайным выборкам соответствующего размера (черные числа обозначают средние значения, серые числа — базовые линии), а планки погрешностей представляют собой стандартное отклонение ±1.
Каждая такая волна работает как отдельный, независимый вычислительный канал. Это позволяет системе параллельно обрабатывать тензорные операции более высоких порядков.
Чжан для понятности придумал отличную аналогию с таможней. «Представьте, — говорит он, — что вы таможенник, и вам надо каждую посылку прогнать через кучу разных аппаратов-сканеров… Наш оптический метод — это, как если бы все посылки и все аппараты объединили в один-единственный этап».
Они создали то, что называют «оптическими крючками»: каждый входной сигнал за одну операцию сразу цепляется к правильному выходу.
Интересно, что вся эта «магия» происходит пассивно, то есть без затрат энергии и без каких-либо внешних управляющих схем. Это не только радикально снижает энергопотребление, но и сильно упрощает интеграцию такой системы.
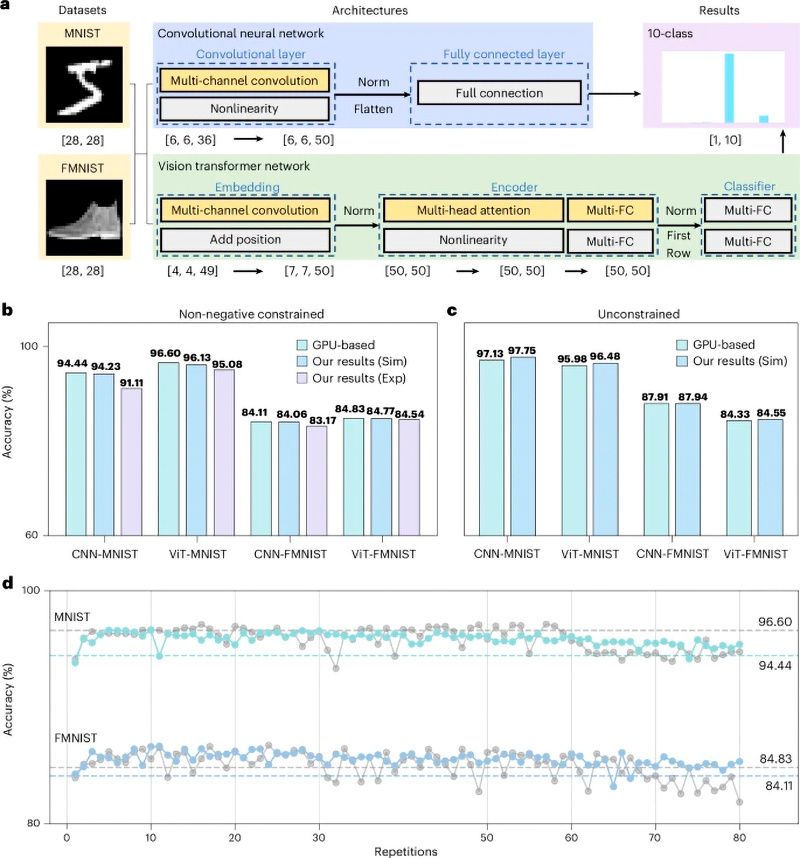
a , Обзор полных конвейеров обработки для CNN (синяя область) и сети ViT (зеленая область). FC, полное соединение; Norm, нормализация. CNN включает сверточный слой и полностью связанный слой, в то время как сеть ViT включает слой внедрения, кодер и классификатор. Выделенные желтым шаги реализованы с использованием POMMM, в то время как остальные компоненты выполняются на GPU. b , Тесты прямого развертывания неотрицательных ограниченных весов, обученных на GPU, в различных сетях и наборах данных на моделировании POMMM и прототипе (матрицы путаницы показаны на дополнительном рисунке 12 ). Sim, моделирование; Exp, эксперимент. c , Тесты прямого развертывания пошаговых неограниченных весов, обученных на GPU, в различных наборах данных на моделировании POMMM (матрицы путаницы показаны на дополнительном рисунке 15 ). d . Сравнение точности вывода ONN на основе POMMM с различными ошибками вычисления (связанными с повторениями элементов). Цветные кривые соответствуют моделям CNN, серые кривые — моделям ViT, а пунктирные линии — соответствующим базовым линиям неотрицательных моделей на основе графических процессоров.
Профессор Чжипэй Сунь, руководящий в Аалто группой фотоники, подтвердил, что метод отлично работает на разных оптических платформах.
В планах — интегрировать всю эту вычислительную архитектуру прямо в фотонные чипы. Если это удастся, сложные ИИ-задачи будут решаться с почти нулевым расходом энергии.
Когда появится в «железе»
Это не такое уж далёкое будущее – команда исследователей ожидает, что технология появится в коммерческом «железе» довольно быстро.
a , Предварительная конструкция параллельного оптического тензорно-матричного умножения с помощью расширения POMMM с мультиплексированием по длине волны. Вверху: упрощенный прямой поток тензорно-матричного умножения. Внизу: подробная взаимосвязь между линейными фазами, длинами волн и позициями. b , Демонстрация мультиплексирования по длине волны POMMM двумя комплексными матрицами. Норм., нормализация. «S» и «J» — это действительная и мнимая части комплексной матрицы A , соответственно, которые модулируются длинами волн 540 нм и 550 нм. После двух длин волн мультиплексирования POMMM они соответственно выполняют тензорно-матричное умножение с действительной частью «T» и мнимой частью «U» комплексной матрицы B для получения полной комплексной результирующей матрицы (промежуточные результаты и исходные оптические поля показаны на Дополнительном рис. 17 ). c , Теоретическая вычислительная мощность по сравнению с существующими парадигмами оптических вычислений (Дополнительная таблица 1 ). Звездочка обозначает мультиплексирование на нескольких длинах волн. Вертикальная ось представляет собой однократный вычислительный параллелизм ( N i указывает, что временная сложность, необходимая цифровой платформе для выполнения этого вычисления, составляет O( N i )), а горизонтальная ось указывает фактический вычислительный масштаб, достигнутый в экспериментах (обозначенный меньшим измерением). d , практическая оценка энергоэффективности. DMD, цифровое микрозеркальное устройство; LCoS, жидкий кристалл на кремнии; VCSEL, лазер с вертикальным резонатором и поверхностным излучением; GOP J − 1 , гига (10 9 ) операций на джоуль. Вертикальная ось обозначает энергоэффективность, а горизонтальная ось представляет различные платформы устройств. Каждая кривая соответствует вычислительной парадигме с определенным уровнем теоретической вычислительной мощности. Крайняя левая точка данных указывает фактическую производительность прототипа.
По оценкам доктора Чжана, на интеграцию в платформы, которые создают крупные IT-компании, уйдёт от 3 до 5 лет. Зачем это нужно?
Такие системы кардинально ускорят ИИ в тех областях, где счёт идёт на доли секунды: анализ изображений в реальном времени, сложные научные симуляции, да и те же большие языковые модели.
Кроме того, это поможет решить проблему энергопотребления нейросетей — проблему, которая с каждой новой моделью ИИ становится всё острее. Возможно, мы действительно на пороге появления нового поколения оптических компьютеров.



![a , Экспериментальные результаты POMMM в сравнении с результатами на основе GPU. Вверху: неотрицательное матричное умножение [20, 20] × [20, 20] (исходное оптическое поле получено на b ). Внизу: действительное матричное умножение [10, 10] × [10, 10] (исходное оптическое поле получено на дополнительном рис. 6 ). Красные элементы представляют отрицательное значение. b , Сравнение между необработанным оптическим полем, полученным камерой qCMOS (внизу), и моделированием (вверху) POMMM. Масштабная линейка составляет 20 пикселей (92 мкм). Каждая яркая точка соответствует элементу в результирующей матрице. c , Сравнение экспериментальных результатов POMMM и MMM на основе GPU. Слева: средняя средняя абсолютная ошибка (MAE). Справа: средняя нормализованная среднеквадратическая ошибка (RMSE). Горизонтальная ось указывает различные размеры матриц. Каждый столбец показывает среднее значение MAE или RMSE по 50 случайным выборкам соответствующего размера (черные числа обозначают средние значения, серые числа — базовые линии), а планки погрешностей представляют собой стандартное отклонение ±1.](https://avatars.dzeninfra.ru/get-zen_doc/271828/pub_69187046630c374577913294_691870f01cc2ee3c0b0a43d9/scale_1200)